
Google Developer Groups DevFest

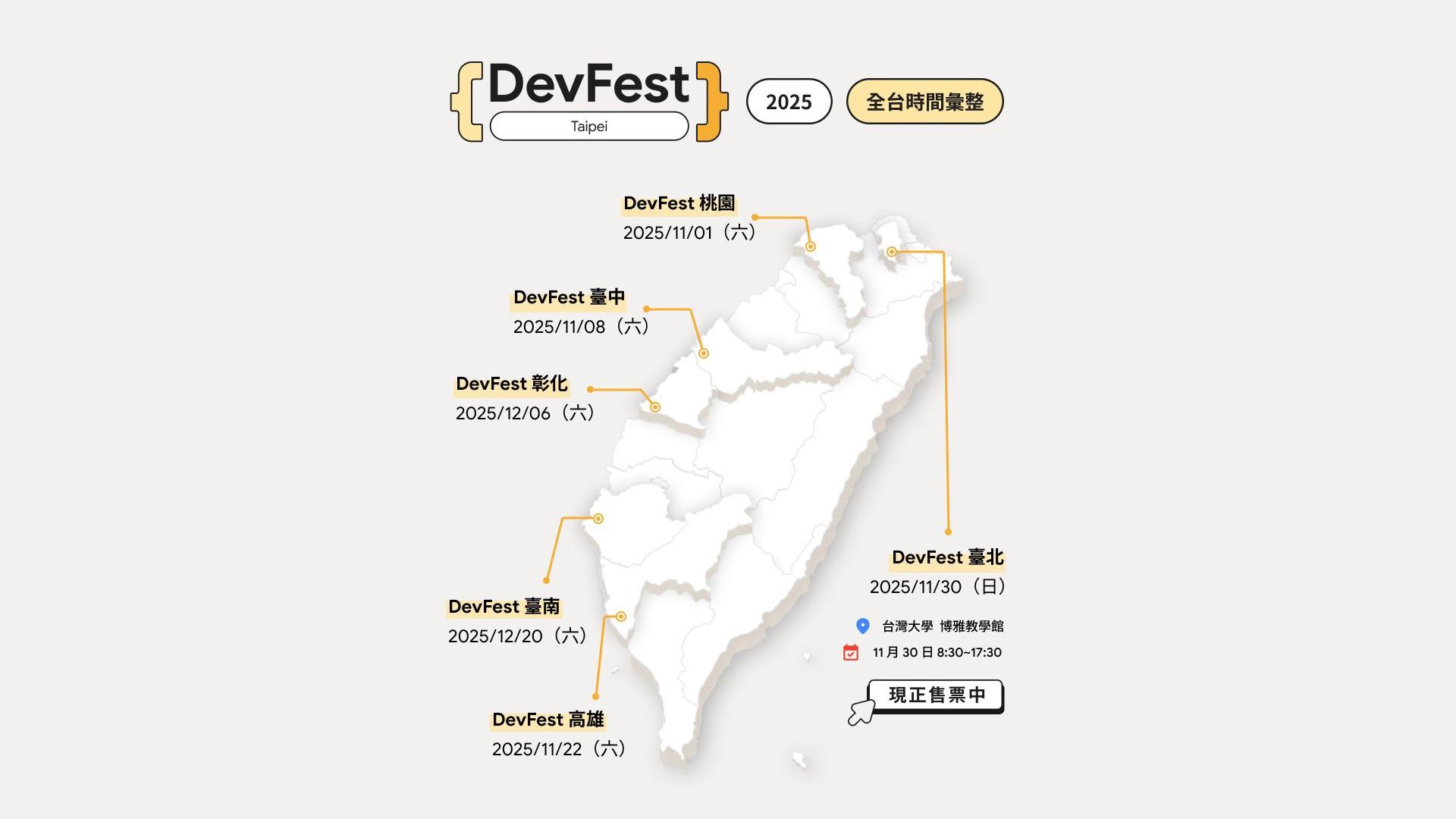
十月初的時候從 GDG 網站看了一下近期有什麼活動,沒有想太多就報名了 DevFest,沒想到是這麼大型的全天性活動。除了台北場之外,還有桃園、台中、彰化、台南、高雄場次可以參加,世界各地的各個城市也會在這段時間舉辦年度技術大會。
今年台北場的地點是在台大博雅教學館,超過 1600 位的使用者表示有參與意願,實際到場的人數也確實很多。安排上午場四軌、下午場六軌,有七大主題:Cloud、AI/Machine Learning、Web Technology、Fluter、Firebase、Android、Go,其中 AI/Machine Learning 是比較熱門的分享主題。
全程共有 38 位講者,主要用中文,少數幾場是全英文進行,講者以兩種形式分享,分別是 40 分鐘的技術分享,以及 2.5 小時的工作坊。
這次只有參與技術分享的部分,從上午到下午,聽了四場半的議程,其中三場是與 AI/Machine Learning 相關的主題,聽完發現沒有多餘的精力參與工作坊了,工作坊就留給未來體驗吧~
兩場與 AI/Machine Learning 相關的議程重點整理
畢竟是 Google Developer Groups 舉辦的技術大會,大部分的分享其實都與 Google 的產品高度相關,搭配共筆重點整理成以下內容:

「Gemini CLI × Spec Kit:重新定義 AI 協作開發」重點整理
在這場議程,講者先是強調為何要以終端機操作 AI 模型,接著帶出 Google 新推出的開源 AI agent 產品 Gemini CLI,介紹 Gemini CLI 在時下的核心優勢有哪些,最後以實際經驗,比較同樣是在終端機與 AI 協作開發的兩個工具 Spec Kit 與 OpenSpec 的使用差異。
對於開發者來說,目前 Gemini CLI 的優勢在於有充足的免費使用額度,Gemini 2.5 Pro 支援百萬 token 的 context window,還可透過 MCP (Model Context Protocol) 擴充功能連接其他軟體工具,避免視窗頻繁切換。
使用時 Gemini CLI 是以 ReAct 推理框架完成錯誤修正與複雜任務需求,詳細內容可在 Gemini CLI: your open-source AI agent 與 Gemini Code Assist 查看完整介紹。
規格驅動開發 SDD
在開發上如果想要降低 AI 失控的風險,規格驅動開發(Spec-Driven Development, SDD) 是目前比較多人討論的解決方案之一,其協作方式是先撰寫清晰、結構化的規格文件,並將自然語言的規格文件納入版控,持續修正迭代。
使用 Spec Kit 的四大步驟
- /specify:聚焦使用者需求與成功標準,建立共識基礎
- /plan :決定技術堆疊與系統架構,建立可執行的實施計畫
- /tasks :分解成可獨立執行的小任務
- /implement :AI 根據任務規格,逐步生成程式碼
Spec Kit 輔助指令
- /speckit.constitution 建立專案原則
- /speckit.specify 建立規格
- /speckit.plan 建立技術實作計畫
- /speckit.tasks 拆解為任務
- /speckit.implement 執行實作
- /clarify :釐清規格中未明確的區塊
- /checklist:產生自訂品質檢查清單,驗證區求的完整性、清晰度與一致性
- /analyze :跨產物一致性與覆蓋度分析
Spec Kit 與 OpenSpec 工具選擇與實務建議
講者認為 Spec Kit 適合 0 ~ 1 的開發情境,規則較嚴謹;OpenSpec 適合 1 ~ 100 開發情境,更彈性、更靈活。「規格驅動開發」的方法論,不適合一次處理太大的需求顆粒,其次是需要具備一定的軟體工程能力才能駕馭這些工具。無論選擇哪一種工具,產出的程式碼一定要全部讀過。

「從零開始到實戰:Gemma-3-270M 預訓練與應用心得分享」重點整理
講者先是說明訓練大語言模型的動機,接著介紹 Gemma 3 系列模型的特色,增強 Gemma-3-270m 的繁體中文能力之後,再以此模型實作兩個有趣的應用:PTT 鍵盤俠模型、唐伯虎模型。
Gemma 和 Gemini 都是 Google 的大語言模型,主要差異在於 Gemma 適用於本地或私有環境,以文字為主,而 Gemini 是以雲端環境為主,還能用多模態方式應用。會需要自行訓練模型者,大部分是基於這三種原因:
- 隱私考量:金融、國防等特定敏感領域不能將資料上雲。
- 領域專精:通用模型無法滿足特定領域高度專業化的需求。
- 成本控制:小規模尚可依賴雲端模型,規模化後使用自訓練的模型更經濟實在。
Gemma 3 系列模型
- 支援圖片與文字輸入(270M, 1B 僅支援文字)
- 輸入的上下文可達 128K token
- 支援超過 140 種以上的語言(繁體中文能力偏弱)
- 多種參數等級:270M, 1B, 4B, 12B, 27B(可從 Kaggle 或 Hugging Face 下載)
- 可使用函式呼叫
小模型訓練的可行性:幾千個樣本即可看到明顯效果
講者使用增強繁體中文能力後的 OOO 模型,展示了兩個有趣的應用,都是基於某種對話特色而回覆訊息的模型,分別是「PTT 鍵盤俠模型」與「唐伯虎模型」。PTT 鍵盤俠模型,會以很辛辣的方式對答,而唐伯虎模型,會以七言絕句的方式回應,即使是 270M 參數也能做出有趣的應用!
講者提到訓練「PTT 鍵盤俠」所使用的訓練資料,是使用現成的大語言模型直接產生幾千筆資料,而非爬蟲抓下來的,這些生成的資料非常符合講師的期望,人工篩選後,才將資料使用 8 張 GPU B200(跑 17 分鐘),最後完成「PTT 鍵盤俠模型」。
HackMD 多人共筆的有趣體驗
有一場議程接近 300 位參與者,當中有一群參與者會一起有默契或沒默契的在 HackMD 上面共筆議程內容。有的人負責簡報文字,有的幫忙補圖片或延伸的超連結,還有的會把口述的實際案例記錄下來,當然有時候還是會遇到誤刪或重複的狀況,這些都蠻有趣的!
結語
報到的時候,會拿到活動識別證,要自行寫上名字,識別證有兩種顏色的掛繩可以選,如果不想被攝影師拍攝,就使用黃色的掛繩。除了會拿到識別證之外,還會有一張天瓏書局的百元折價券(是盲鳥票限定禮),最後是一張貼紙,不知道為什麼,只要收到貼紙就很開心 ♩♫♬~
以第一次參加 GDG DevFest 活動來說,覺得活動位置很便捷,抵達現場後也因為有事前公開場地平面圖,所以幾乎不太需要花時間找議程位置,每個空間都有提供 Wi-FI 給參與者使用。
教室座位空間狹小,坐定後就無法走動,建議提早進場卡位,熱門場次最好是上一場就要在裡面。設備電力問題需要自行處理(只有遇到其中一間教室桌面有插座)。
中間午休時間一個小時,距離用餐的地方有段距離,雖然有帶簡餐,但身體還是很誠實的走去速食店買炸物,週末店家人潮眾多,時間要預留多一點,如果不想錯過下午一點的議程,建議還是自備餐點,用餐時間會比較充裕。

參考資料
Gemini CLI: your open-source AI agent